
W dzisiejszym wpisie pokażę jak w kilkanaście minut przygotować sobie zbiór narzędzi ELK (Elasticsearch + Logstash + Kibana) i zacząć analizować tzw. "access logi" z serwera webowego Apache. A to wszystko, stawiając te narzędzia na Dockerze.
Jeżeli nie wiesz czym jest Elasticsearch, zachęcam do zapoznania się z projektem na jego stronie. Po krótce: jest to oprogramowanie służące do przeszukiwania treści w możliwie najszybszy sposób. Treści te muszą być najpierw zindeksowane, co oznacza, że muszą zostać przez nas wcześniej dostarczone. Do tego możemy użyć drugiego narzędzia - Logstasha. Aby wyświetlić dane w przyjazny dla użytkownika sposób, wykorzystać można kolejne z narzędzi - Kibanę. To wszystko tworzy nam łącznie zbiór narzędzi ELK, który jest powszechnie wykorzystywany w wielu firmach zajmujących się tworzeniem oprogramowania.
Z czego będzie składać się nasze środowisko
Na potrzeby tego krótkiego poradnika przygotujemy prostą aplikację opartą o PHP i serwer Apache. W tym celu skorzystamy z gotowego obrazu Dockerowego, podobnie w przypadku pozostałych usług. Następnie utworzymy wolumen, który będzie współdzielony między Logstash'em a Apachem. Logstash będzie odczytywał logi z Apache'a i przesyłał je protokołem sieciowym do Elasticsearch'a. Obok nich postawimy Kibanę, która będzie się łączyła z Elasticsearch'em i wyświetlała dane w postaci wykresu przedstawiającego ilość zdarzeń w czasie.
Przygotowanie aplikacji webowej
Najpierw stwórzmy plik index.php, który będzie naszą "aplikacją" - napisałem aplikacją w cudzysłowiu, ponieważ jedyne co będzie ta aplikacja robić, to odbijać z powrotem parametry zapytania w postaci JSON'a:
<?php
echo json_encode($_GET);Dodajmy także plik docker-compose.yaml. Tutaj będzie się działo dzisiaj najwięcej. Dodajmy najpierw serwis z PHP 8.0 i podmontujmy od razu plik z kodem:
version: '3'
services:
php:
image: php:8.0-apache
volumes:
- "./index.php:/var/www/html/index.php"
ports:
- "80:80"Możesz spróbować uruchomić serwis za pomocą polecenia docker-compose up - ja na razie tego nie będę robił. Na tym etapie musimy się dowiedzieć, gdzie są trzymane access logi. Sprawdziłem to jednak wcześniej i wiem, że znajdują się one w lokalizacji /var/log/apache2/access.log.
Stawiamy Elasticsearch'a i Kibanę
Teraz dodamy sobie usługi, które wymieniłem w śródtytule. Do pliku docker-compose.yaml wstawiamy kolejne sekcje:
services:
elasticsearch:
image: elasticsearch:7.11.1
environment:
discovery.type: single-node
xpack.security.enabled: "true"
ELASTIC_PASSWORD: password
kibana:
image: kibana:7.11.1
volumes:
- "./kibana.yaml:/usr/share/kibana/config/kibana.yml"
ports:
- 5601:5601Zwróć uwagę, że dodaliśmy kilka zmiennych środowiskowych potrzebnych do uruchomienia Elasticsearch'a, m.in. domyślne hasło dla superuser'a o nazwie elastic.
Teraz dodajemy nowy plik z konfiguracją dla Kibany o nazwie kibana.yaml:
server.name: localhost
server.host: "0.0.0.0"
elasticsearch.hosts: http://elasticsearch:9200
elasticsearch.username: elastic
elasticsearch.password: passwordTutaj są wymagane dla Kibany opcje konfiguracyjne, aby Kibana mogła połączyć się z Elasticsearch'em. Możesz na tym etapie także spróbować uruchomić serwisy z pomocą polecenia docker-compose up, ale ja zrobię to później.
Dodajemy i konfigurujemy Logstash'a
Teraz ostatni, najbardziej skomplikowany etap. Najpierw dodajmy kolejną usługę z Logstash'em w pliku docker-compose.yaml:
services:
logstash:
image: logstash:7.11.2Logstash z obrazu Dockerowego działa od razu po starcie usługi i próbuje przetwarzać dane, jeżeli zostały dodane konfiguracje procesów. Działa on tak, że dane przetwarza w tak zwanych pipeline, które składają się z operacji wejścia, filtrów i operacji wyjścia. Nie jestem specjalistą w pisaniu tych konfiguracji, dlatego skorzystamy z gotowego przykładu na stronie Elastica. Tworzę w tym celu plik apache-logs.cfg z zawartością dopasowaną do naszego środowiska:
input {
file {
path => "/var/log/apache2/access.log"
start_position => "beginning"
}
}
filter {
if [path] =~ "access" {
mutate { replace => { "type" => "apache_access" } }
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "apache_access"
user => "elastic"
password => "password"
}
stdout { codec => rubydebug }
}W oryginalnym skrypcie zmieniłem adres, na którym znajduje się Elasticsearch, lokalizację pliku z logami Apache, a także skonfigurowałem odpowiedni login, hasło oraz nazwę indeksu, do jakiego mają polecieć dane z logów.
Domyślnie pliki konfiguracyjne zawierające pipeline znajdują się w katalogu /usr/share/logstash/pipeline. Dlatego w pliku docker-compose.yaml dodaję w serwisie Logstash'a odpowiedni wolumen:
services:
logstash:
volumes:
- "./apache-logs.cfg:/usr/share/logstash/pipeline/apache-logs.cfg"Została nam ostatnia rzecz do zrobienia, jeżeli chodzi o konfigurację środowiska Dockerowego; musimy sprawić, aby Logstash miał dostęp do pliku z logami Apache. W tym celu podmontujemy plik z logami do maszyny hosta, a następnie do Logstash'a:
services:
php:
volumes:
- "./access.log:/var/log/apache2/access.log"
logstash:
volumes:
- "./access.log:/var/log/apache2/access.log"Oraz tworzymy pusty plik access.log w katalogu projektu.
Teraz mamy już wszystko skonfigurowane! Po zbudowaniu serwisów za pomocą polecenia docker-compose up i odczekaniu około minutki na start usług, powinniśmy mieć możliwość wejścia na Kibanę pod adresem localhost:5601:
Możemy zalogować się na konto o nazwie elastic, z hasłem ustawionym w konfiguracji, czyli: password.
Teraz otwieramy menu po lewej stronie, wchodzimy w Stack Management > Index pattern > Create index pattern. Zobaczysz tutaj, że na liście będzie widoczny wcześniej zdefiniowany w pipeline Logstash'a indeks o nazwie apache_access:
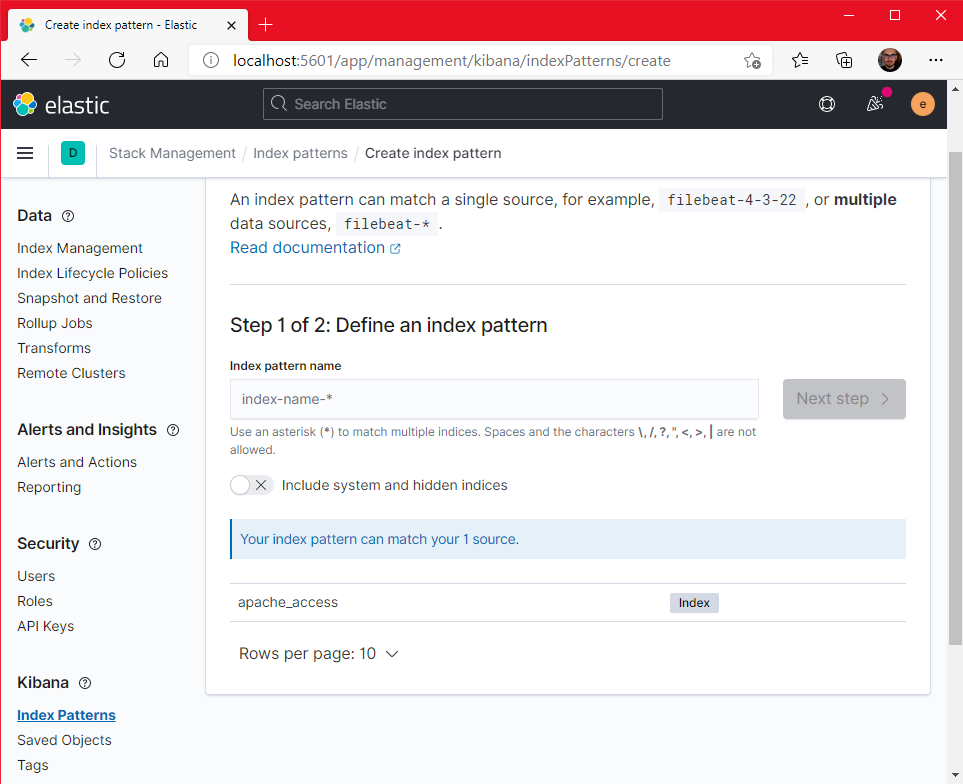
W polu Indeks pattern name wpisujemy "apache_access*", dzięki czemu nasz indeks zostanie "złapany" przez ten wzorzec. Kliknijmy teraz na przycisk Next step. Tutaj w polu Time field wybieramy pole "@timestamp" i zatwierdzamy wybór przyciskiem Create index pattern. Gotowe! Teraz po wejściu w zakładkę Discover w menu będziemy mieć podgląd naszych logów:
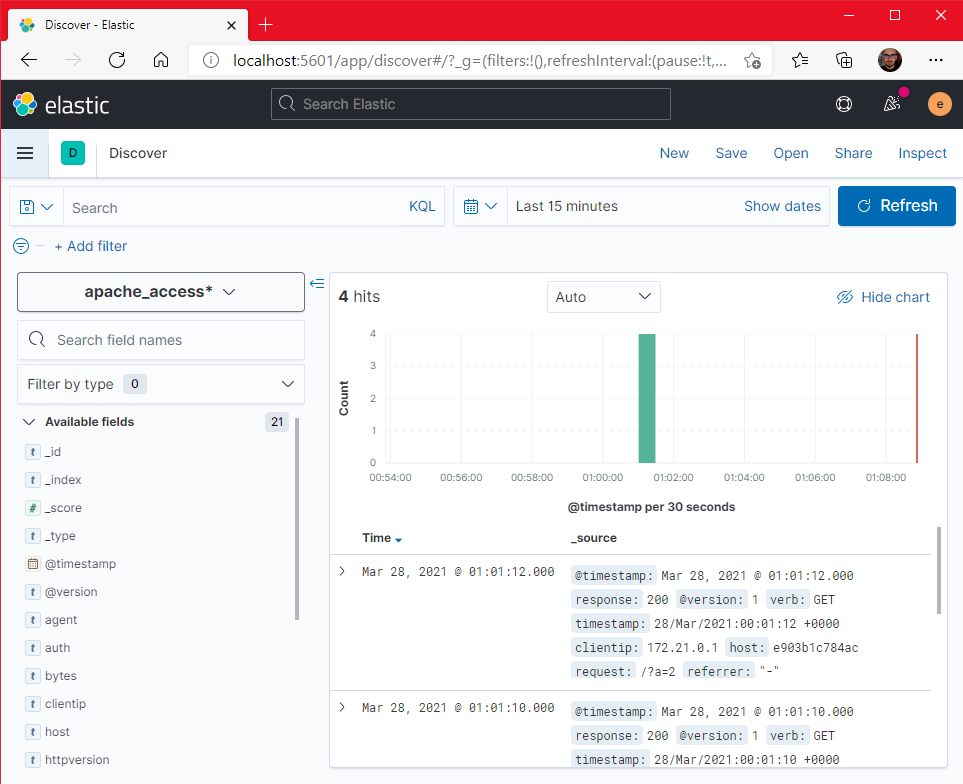
Na moim zrzucie ekranu widzisz, że są już widoczne w logach jakieś żądania. Wynika to z tego, że uruchomiłem już kilka razy stworzoną na początku aplikację. Jak wejdziesz na nią u siebie w przeglądarce, np. na adres http://localhost/?param=1 i odświeżysz widok w Kibanie za pomocą przycisku "Refresh", to zobaczysz, że wpis dla twojego wejścia od razu pojawi się na wykresie.
I to już koniec tego poradnika! Końcową wersję projektu możesz pobrać z mojego repozytorium - mam nadzieję, że po drodze nic mi nie umknęło. Jak zwykle zachęcam do zabawy z kodem, eksperymentowania i poczytania więcej na ten temat - na pewno ta wiedza się przyda, bo są to narzędzia wykorzystywane obecnie w wielu firmach.
Komentarze
Ten wpis nie posiada komentarzy.
Dodaj komentarz
Pola oznaczone gwiazdką (*) są wymagane. Komentarze są wstępnie moderowane i mogą nie pojawić się na stronie.