
Przyzwyczailiśmy się już się do zaawansowanych multimedialnie stron internetowych. Obecnie ciężko znaleźć witrynę, która nie posiadałaby jakichś treści multimedialnych - czy to audio, czy wideo. Jednak nadal sposób nawigowania po nich jest oparty o prostą jak cep metodę - klikanie za pomocą myszy / dotyku w elementy wskazujące na określone miejsca na stronie. Jest to dla mnie tak naturalne, że chcąc przejść na inną podstronę mechanicznie skroluję ekran na samą górę.
A co gdyby wprowadzić dodatkową warstwę nawigacji, bliższą naturalnemu sposobowi komunikacji człowieka z drugim człowiekiem? Dzieje się już tak na smartfonach, gdzie do sterowania urządzeniem możemy używać komunikacji głosowej. Obecnie każdy inteligentny telefon posiada wbudowanego asystenta głosowego, który umożliwia uruchomienie konkretnych aplikacji czy funkcji, które są w nich zaimplementowane.
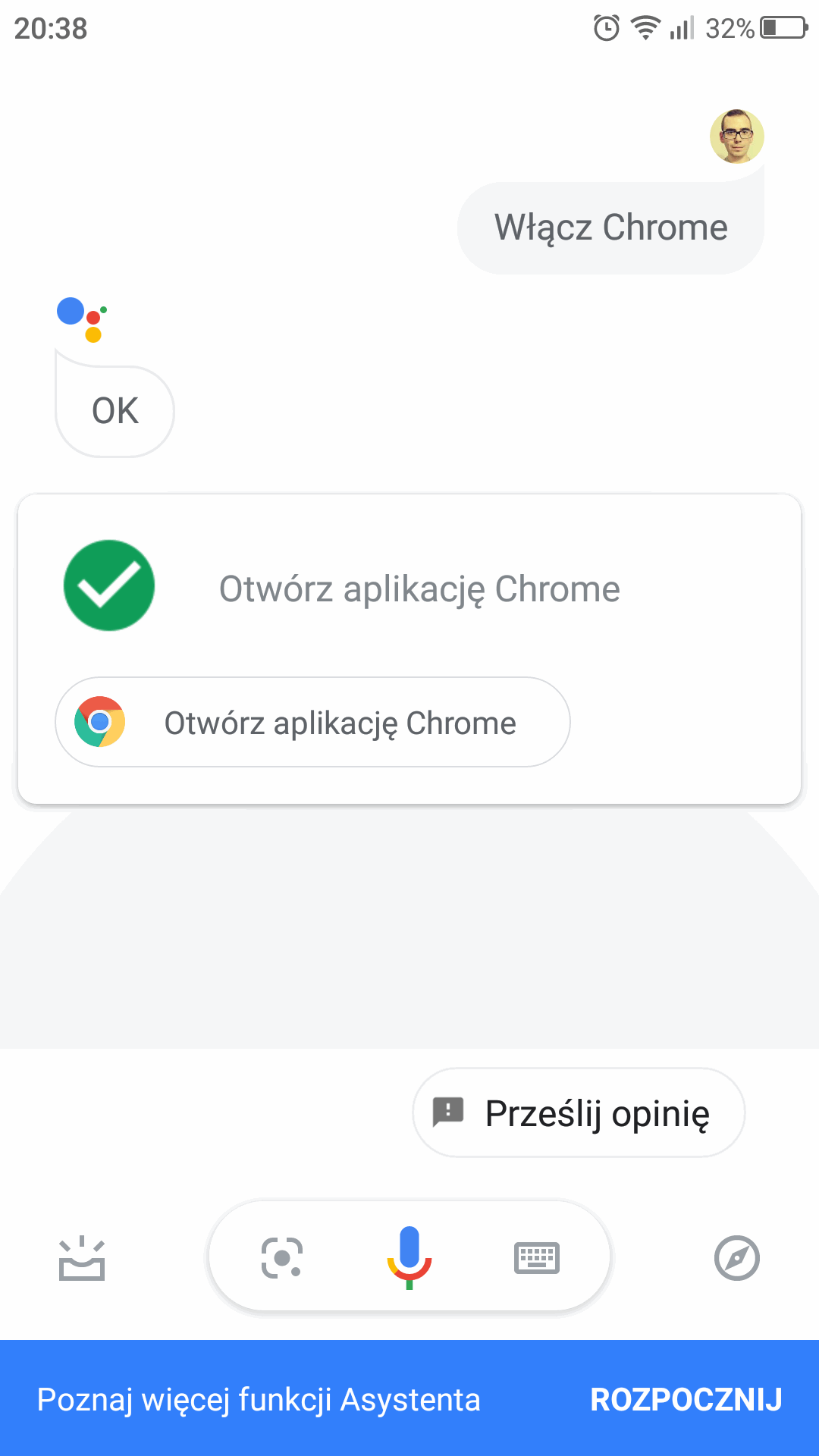
Aplikacje webowe także zmierzają w tym kierunku małymi krokami. Część witryn posiada chatboty, które pozwalają na np. udzielanie odpowiedzi na najczęściej zadawane pytania. Jednak są to rozwiązania z reguły mało elastyczne i pozwalają na sterowane fragmentem funkcjonalności. Obecnie w fazie eksperymentów jest natywne API dla przeglądarek - Web Speech API, które umożliwia w prosty sposób implementację rozpoznawania mowy, co pozwala na np. sterowanie albo wprowadzanie treści głosem.
W dzisiejszym wpisie chciałbym przedstawić, jak napisać prostą funkcjonalność w oparciu o ten interfejs na przykładzie formularza uzupełnianego głosowo.
Uwaga! Tak jak wyżej wspomniałem (i co jest podkreślone na stronie dokumentacji) obecne API jest w fazie eksperymentalnej. To oznacza, że może ulec w każdej chwili zmianom. Dlatego nie zaleca się obecnie z jego korzystania w produkcyjnych rozwiązaniach.
Tworzymy prosty formularz
Najpierw stworzymy szkielet formularza z dwoma polami i 3 przyciskami. Przyciski będą umożliwiały uruchomienie nasłuchu mikrofonu, a trzeci posłuży za przesłanie formularza na serwer. Tworzymy plik index.html i dodajemy do niego zawartość:
<!doctype html>
<html>
<head>
<title>Web Speech API demo</title>
</head>
<body>
<form action="" method="get">
<input id="form-input-name" type="text" name="name"/>
<input id="form-button-name" type="button" value="Głosem"/>
<input id="form-input-comment" type="text" name="comment"/>
<input id="form-button-comment" type="button" value="Głosem"/>
<input type="submit" value="Wyślij"/>
</form>
</body>
</html>Następnie dodajemy sekcję <script> (dla uproszczenia w tym samym pliku, po sekcji <html> z następującym kodem:
var SpeechRecognition = SpeechRecognition || webkitSpeechRecognition;
var SpeechGrammarList = SpeechGrammarList || webkitSpeechGrammarList;
const recognition = new SpeechRecognition();
recognition.grammars = new SpeechGrammarList();
recognition.continuous = false;
recognition.lang = 'pl-PL';
recognition.interimResults = false;
recognition.maxAlternatives = 1;Powyższy kod inicjalizuje obsługę rozpoznawania mowy i udostępnia jego możliwości poprzez obiekt klasy SpeechRecognition. W powyższym przykładzie konfiguracja została tak przygotowana, aby zwracać jedną, dopasową frazę w języku polskim. Tak! Język polski jest obsługiwany i działa to bardzo dobrze.
Następnie oprogramowujemy zdarzenia, które API udostępnia:
recognition.onaudiostart = () => {
console.log('You can speak now...');
};
recognition.onaudioend = () => {
console.log('Thank you for speech!');
};
recognition.onerror = (event) => {
if (event.error === 'not-allowed') {
console.log('Permission denied.');
} else {
console.log('Some errors occurred.');
}
};
document.querySelector('#form-button-name').addEventListener('click', () => {
recognition.onresult = (event) => {
const result = event.results[event.results.length - 1][0].transcript;
document.querySelector('#form-input-name').value = result;
}
recognition.start();
});
document.querySelector('#form-button-comment').addEventListener('click', () => {
recognition.onresult = (event) => {
const result = event.results[event.results.length - 1][0].transcript;
document.querySelector('#form-input-comment').value = result;
}
recognition.start();
});Podstawowe dostępne zdarzenia:
- onaudiostart - zdarzenie wywoływane, kiedy mikrofon zaczyna nasłuchiwać. Możemy tutaj np. pokazać komunikat, że aktualnie trwa nasłuchiwanie.
- onaudioend - zdarzenie wywoływane, kiedy mikrofon przestaje nasłuchiwać (ale próbka jest w trakcie przetwarzania).
- onerror - zdarzenie wywoływane, kiedy wystąpi błąd (np. użytkownik nie przyznał uprawnień stronie do używania mikrofonu. W powyższym przypadku sprawdzamy ten przypadek.
- onresult - zdarzenie wywoływane, kiedy została dopasowana fraza do próbki głosu.
- onnomatch - zdarzenie wywoływane w przypadku, kiedy nie udało się rozpoznać powiedzianej frazy.
Więcej dostępnych zdarzeń możesz znaleźć w dokumentacji. W powyższym kodzie zapinam się na akcję kliknięcia w przycisk - po kliknięciu ustawiam callback i rozpoczynam nasłuchiwanie. Po rozpoznaniu mowy wynik jest zapisywany w polu tekstowym.
Jak możesz zauważyć, kod jest bardzo prosty a efekt wysoce zadowalający. Sam napisałem prostą funkcjonalność nawigowania, która widoczna jest na tej stronie po wejściu na smartfonie na przeglądarce Google Chrome (i nie było to dla mnie trudne, chociaż jestem backendowcem 😊) .
Ciekawa technologia, ale nie dla wszystkich
Jakie są wymagania opisanej wyżej technologii? Po pierwsze: kompatybilna przeglądarka. Obecnie na desktopie w pełni obsługuje to API Google Chrome (przetestowałem też Microsoft Edge i nie działa ono tutaj tak jak bym się spowiedziewał). Na urządzeniach z Androidem rozwiązanie działa bezproblemowo na przeglądarce Google Chrome oraz Microsoft Edge.
Oprócz tego wymagany jest dostęp do internetu - nie ma co ukrywać, rozpoznawanie musi działać natychmiastowo aby był sens z jego korzystania, a jest do tego potrzebna spora moc obliczeniowa. Dlatego przeglądarka przesyła próbkę na serwery Google, gdzie dalej jest przetwarzana poza urządzeniem.
Testowanie funkcjonalności lokalnie
Wyżej opisane API (podobnie jak inne API dostępne w przeglądarce zbierające dane z sensorów urządzenia) do działania wymaga serwera z obsługą HTTPS. Jedynym wyjątkiem od tej reguły jest localhost. Oprócz tego pliki statyczne można serwować z dysku (bez serwera web) i je tak testować.
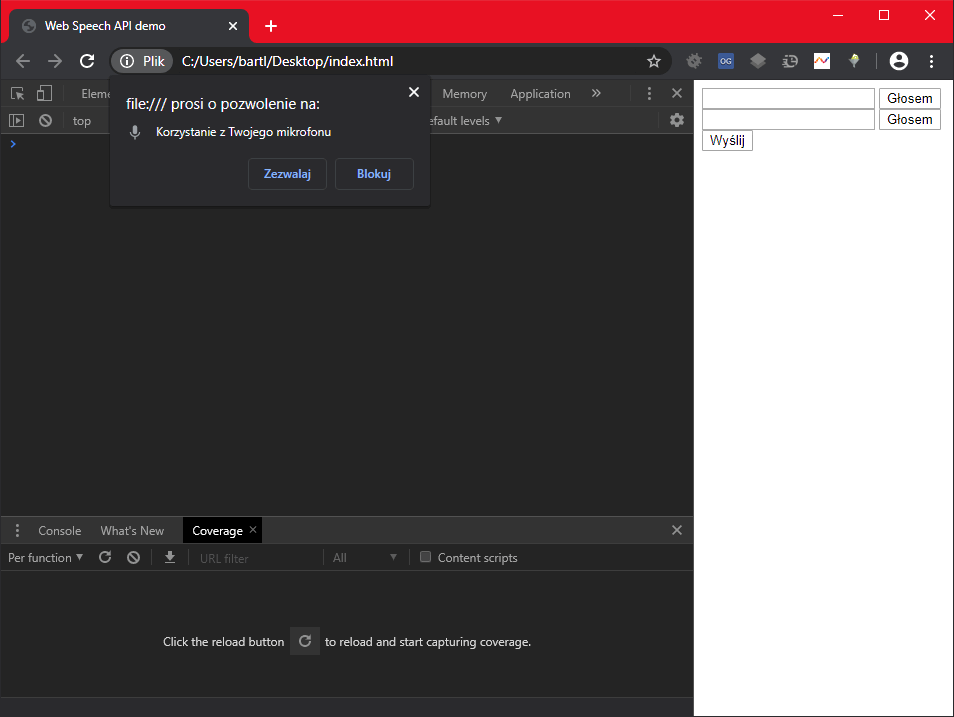
Zachęcam jak zawsze do zabawy i poznawania nowych rzeczy. Powyższy formularz w raz z kodem możesz pobrać stąd.
Komentarze
Ten wpis nie posiada komentarzy.
Dodaj komentarz
Pola oznaczone gwiazdką (*) są wymagane. Komentarze są wstępnie moderowane i mogą nie pojawić się na stronie.